REMATIQ · RESEARCH AGENT · PRODUCT CASE
Trust is the product.
TRUST IS THE PRODUCT
WHAT WE WERE ASKED
Take the research agent from prototype to trusted every day
REMATIQ is a MedTech compliance platform in three layers: the compliance graph, workflows, and a general-purpose research agent. This case is only about the third layer, the one that handles long-tail Q&A and one-off documents.
- Five areas: regulatory Q&A, internal-data Q&A, document generation, lifecycle, citing sources
- Two hard constraints: every answer needs a verifiable source; the agent works on the connected graph
- Four deliverables for Monday: ① reprioritized user stories ② align with Stefan ③ align with Anton ④ prototype
WHERE THE RESEARCH AGENT SITS
Where the research agent sits in REMATIQ: it reads and writes on top of the graph
From REMATIQ's site. The research agent is the top-layer Documentation Agents, reading and writing on the Ontology and Audit Graph. REMATIQ.COM
THE ARGUMENT, IN ONE BREATH
A citation is a contract the backend must honor.
First confirm the industry baseline, then the solution proven in production, then name the frontier, then the solution and deliverables. Baseline and extension stay clearly separate.
- Verifiable citation is the industry floor; faithfulness and relevance are largely solved
- reduce-hallucination ships these two layers in production
- The real frontier is supportiveness, and it depends on the user's intent
- Solved with an intent agent and “surface, not decide”
THE FLOOR, ALREADY SOLVED
An answer without a source is nearly useless.
This is the floor in regulated industries. Medical and legal AI long ago made “answers with clickable sources” standard: each sentence anchors to the source, hover to preview, click to verify.
OpenEvidence
Clinical Q&A; cites peer-reviewed sources sentence by sentence; declines when unsupported OPENEVIDENCE
Harvey
Legal; cites the specific clause/paragraph, click back to verify HARVEY
NotebookLM
RAG + inline citations; ~13% response-level hallucination (vs ~40% without grounding) NOTEBOOKLM
So “showing citations” is just the entry ticket; the real moat is backend verification. It solves the first two pillars: faithfulness (the quote is real) and relevance (on topic).
PRODUCTION CANON
reduce-hallucination: take the first two pillars into production
It borrows proven techniques from interrogation science for getting a knowing witness to tell the truth PEACE · SUE: treat each LLM node as a witness, build five gates, and validate in production 2,818 TASKS. At this point, faithfulness and relevance are both solved.
“Ask-and-actually-check” effect g≈0.80; in the same prompt, fields with an abstention exit had zero corrections. VERIFIABILITY STUDY PRODUCTION A/B OPEN SOURCE · GITHUB
THE FRONTIER · THIRD PILLAR
Supportiveness: does the cited passage actually support the claim?
Real and relevant does not mean supportive. A citation that resolves but does not support the claim (misgrounding) is worse than none, because it manufactures false trust. Support vs contradiction depends on which direction the user argues.
link valid / relevant · looks fine
actually supports the claim · fails in substance
TWO AGENTS · PROACTIVENESS
Beyond answering, a second agent that infers intent
The execution agent grounds the answer; the intent agent starts from the current question and pulls in context ring by ring to infer what the user is really arguing.
Combine the layers to infer intent, then decide which citation to use and resolve supportiveness with both directions. When intent is unclear, show both and let the human choose. Design after KeyCite: direction is a review flag, not a verdict. WESTLAW KEYCITE
WORKED EXAMPLE · no UI, just the process
“SOP-042 meets ISO 14971’s residual-risk requirements.”
Retrieve ISO 14971 §8 and SOP-042 §6; on topic.
Five gates:
✓ the triple (value · source · verbatim quote)
✓ verbatim check: ‘residual risk shall be evaluated’ does exist in §8
✓ provenance = stated
✓ real check passed
→ faithfulness + relevance solved
Read session + draft: this sits in the ‘gap assessment’ section, in a self-assessing tone.
Pull in history and scene →
Intent unclear: prove compliance, or find the gap?
→ unclear, don't decide for the user
▲ Supports ISO 14971 §6 ‘risk control’ → backs ‘meets’
▼ Contradicts §8 requires post-market residual-risk monitoring; SOP-042 §6 has no such step → exposes a gap
→ whichever is picked anchors the deliverable and feeds back as an intent signal
Same draft sentence: real and relevant; but which direction it supports depends on intent. Finding the opposing evidence is gap analysis. (Clause numbers are illustrative; the real UDM paragraph governs.) ISO 14971 · example SOP-042 · example
REPRIORITIZED USER STORIES
Citation is the spine, yet the PRD filed it under NICE; promote it to P0
Basis: both citation stories are NICE and unbuilt in the PRD, while positioning and strategy treat “verifiable” as core. The “too long” feedback is structural; progressive disclosure fixes it. PRD PILOT FEEDBACK
ALIGN WITH STEFAN · CUSTOMER NEED
Align with Stefan (1): validate the customer-need assumptions first
Alignment = come with a judgment to confirm or refute, not open-ended questions. Frame each question as “which product decision does it settle for me”.
Validates: progressive disclosure vs blunt truncation · evidence: revisit Marcel / Paul's langfuse traces
Validates: how aggressive abstention should be · a wrong conclusion in a submission costs far more than “not in the library”
Validates: whether the supportiveness feature is worth building, and how to present it
Validates: whether my area-priority order is right
I bring not a question list but a judgment plus a set of assumptions for Stefan to confirm or refute.
ALIGN WITH STEFAN · ML & DATA
Align with Stefan (2): can the data and ML support the citation contract?
- Retrieval granularity: can we reliably retrieve at UDM paragraph / span level?
- Verbatim verification: deterministic string-match against UDM; at what point does OCR normalization need a bounded fuzzy matcher? (the cost fork)
- Stance classifier: do we have / can we build claim-evidence entailment? Is it accurate on conditional regulatory language?
- Intent agent: ML (embedding / clustering over the session) or just a prompt?
- How is the abstention threshold calibrated? What triggers it?
- Does each UDM paragraph have a stable, resolvable, version-stamped anchor?
- Are typed links queryable at answer time? (so ‘inferred’ shows the real relation chain, not a vector guess)
- Is revision / draft history recorded and accessible? (the intent agent's lifeblood)
- Is org / project scope enforced at the data layer?
In one line: if these hold, the spine ships in v1; if not, fix the data first, don't build flourishes.
ALIGN WITH ANTON · COST
Align with Anton (1): get the real cost per item; open with the cost asymmetry
“The model already retrieves the spans; this is just an output-format constraint, no new infra”
“Medium” only if OCR text normalization needs a bounded fuzzy matcher, the one estimate to nail down with Anton
only on sign-off, high-stakes answers, not every lookup
needs Anton to scope: async over session logs? on the existing background-execution layer? latency / cost / data dependencies?
The argument to Anton: most of the spine is cheap; the pricey half (the verifier) is exactly the line between a demo and a trusted tool. Skip it and the product gets more dangerous, not just less impressive.
ALIGN WITH ANTON · ITERATION & RISK
Align with Anton (2): sequence v1 / v2 / v3 by cost, and lay out the risks
- determinism on messy OCR docs (→ fuzzy-match threshold)
- the intent agent's data dependency (are revisions logged)
- proactivity × access-control intersection
- version correctness: when a source changes, what happens to old citations
One-line cost story: v1 is a prompt and a schema; v2 is one cheap distilled model plus a pricey intent agent; v3 is mostly governance.
A CURSOR FOR COMPLIANCE DOCS · CLICKABLE DEMO
A Cursor for compliance docs: agents on the left, document on the right, verification in the middle
Multiple compliance tasks in parallel (like Cursor sessions) · bottom-left always-on intent agent: shows what it read, what was added to input, the current intent
Grounded trace: read → verbatim verify ✓ → judge stance → both directions · evidence folded into an auditable log · click a citation to peek the source
The generated compliance doc, editable, with version history · revisions feed the intent agent · attest = attestation
No backend, one scripted case (BP Monitor / SOP-042 / ISO 14971). Verification is a real JS verbatim string-match. ▶ LIVE DEMO · /en/demo highlight · #go
6 capabilities · 6 requirements (captured from the live demo)
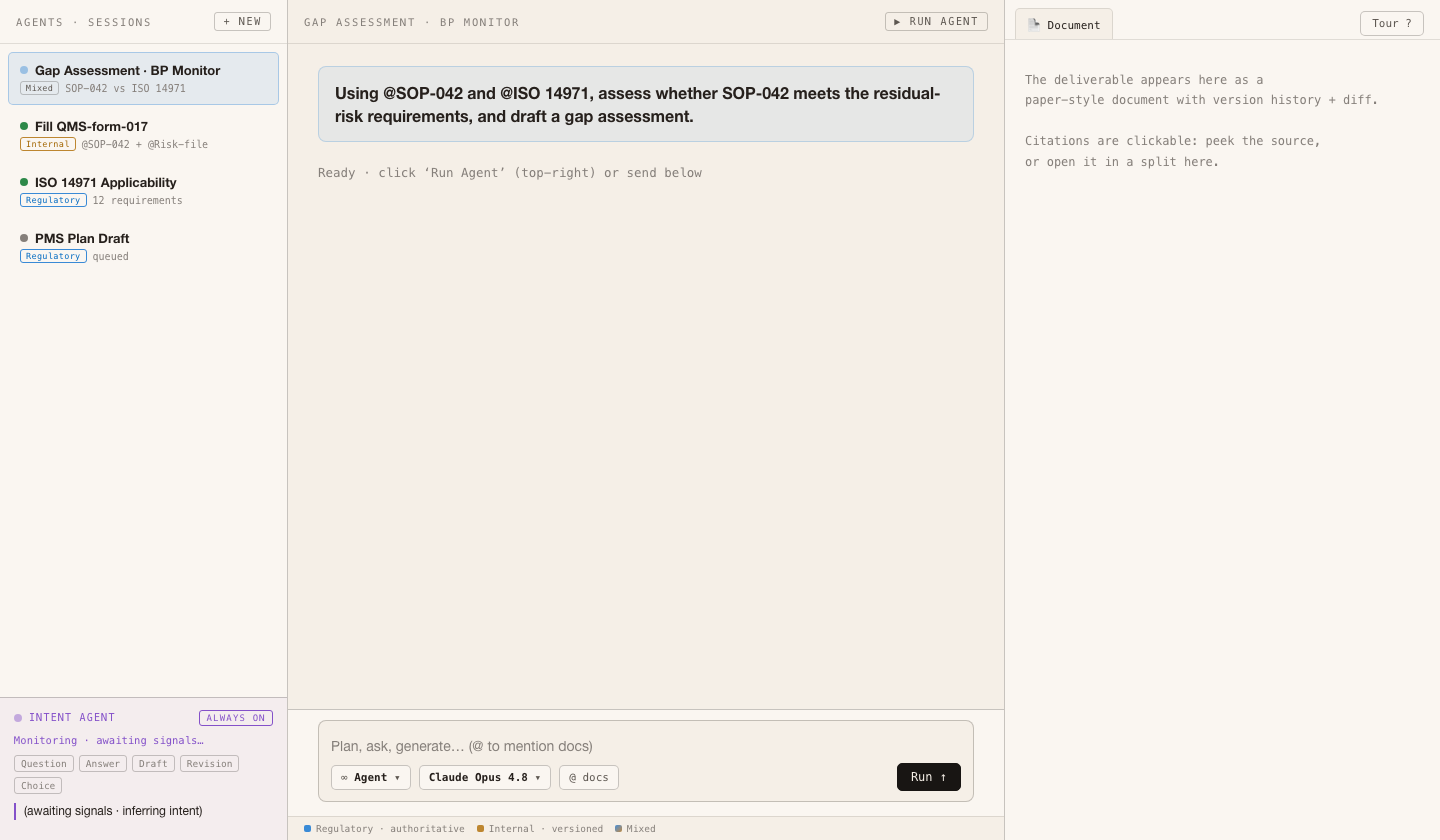
Req: answers traceable · internal/regulatory boundary · intent visible
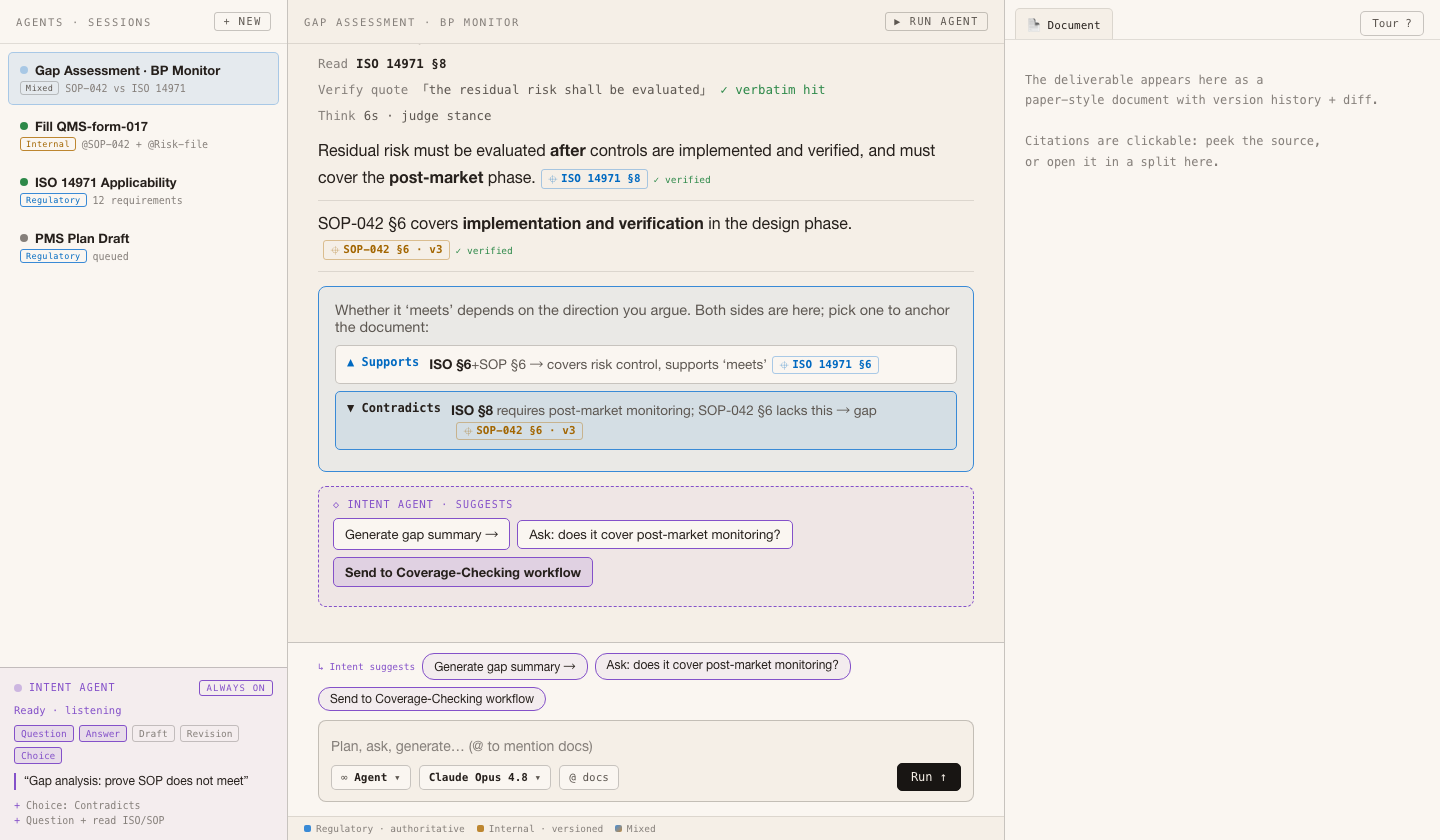
Req: faithfulness + relevance + supportiveness
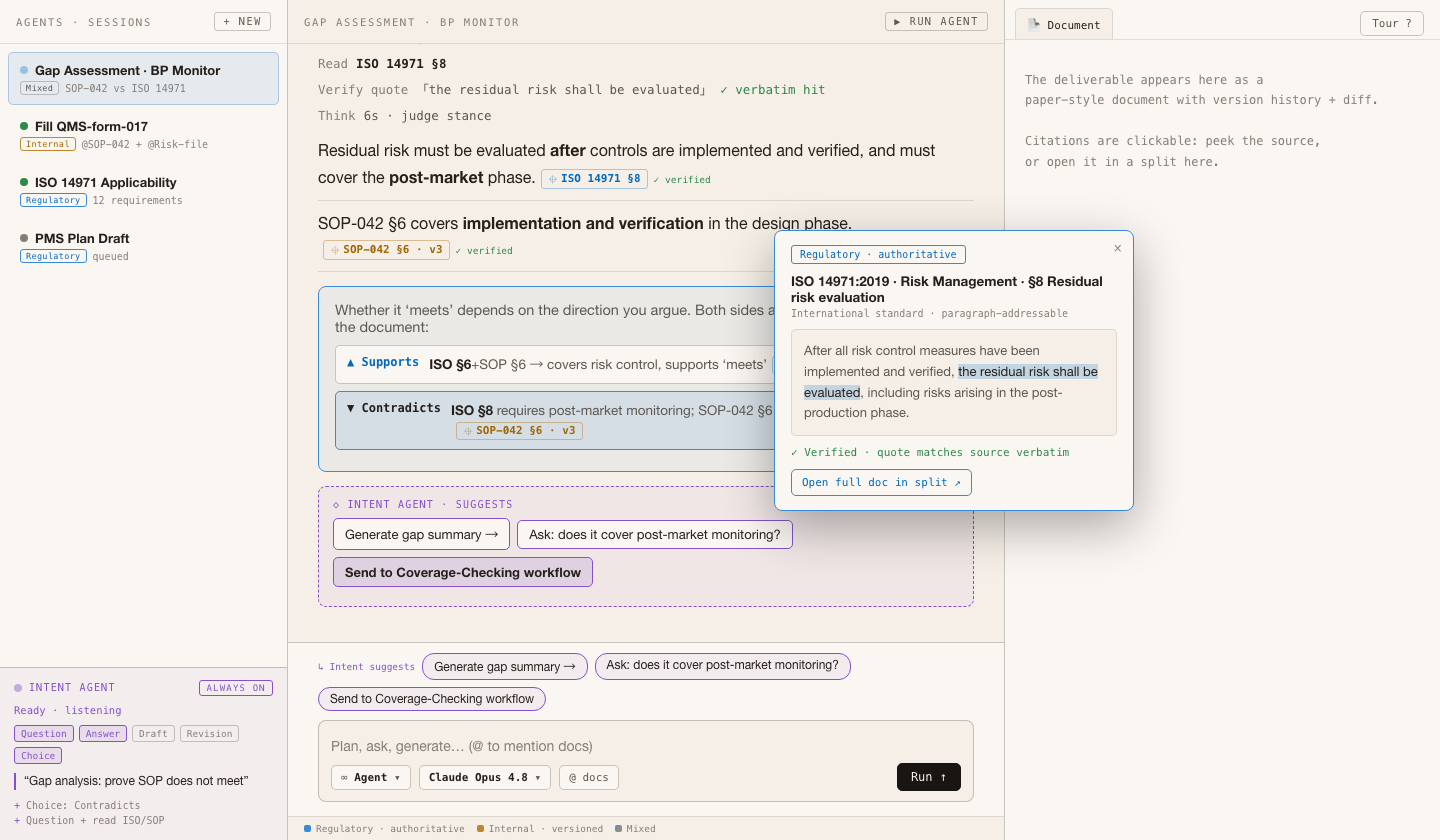
Req: click back to verify (regulation down to paragraph)
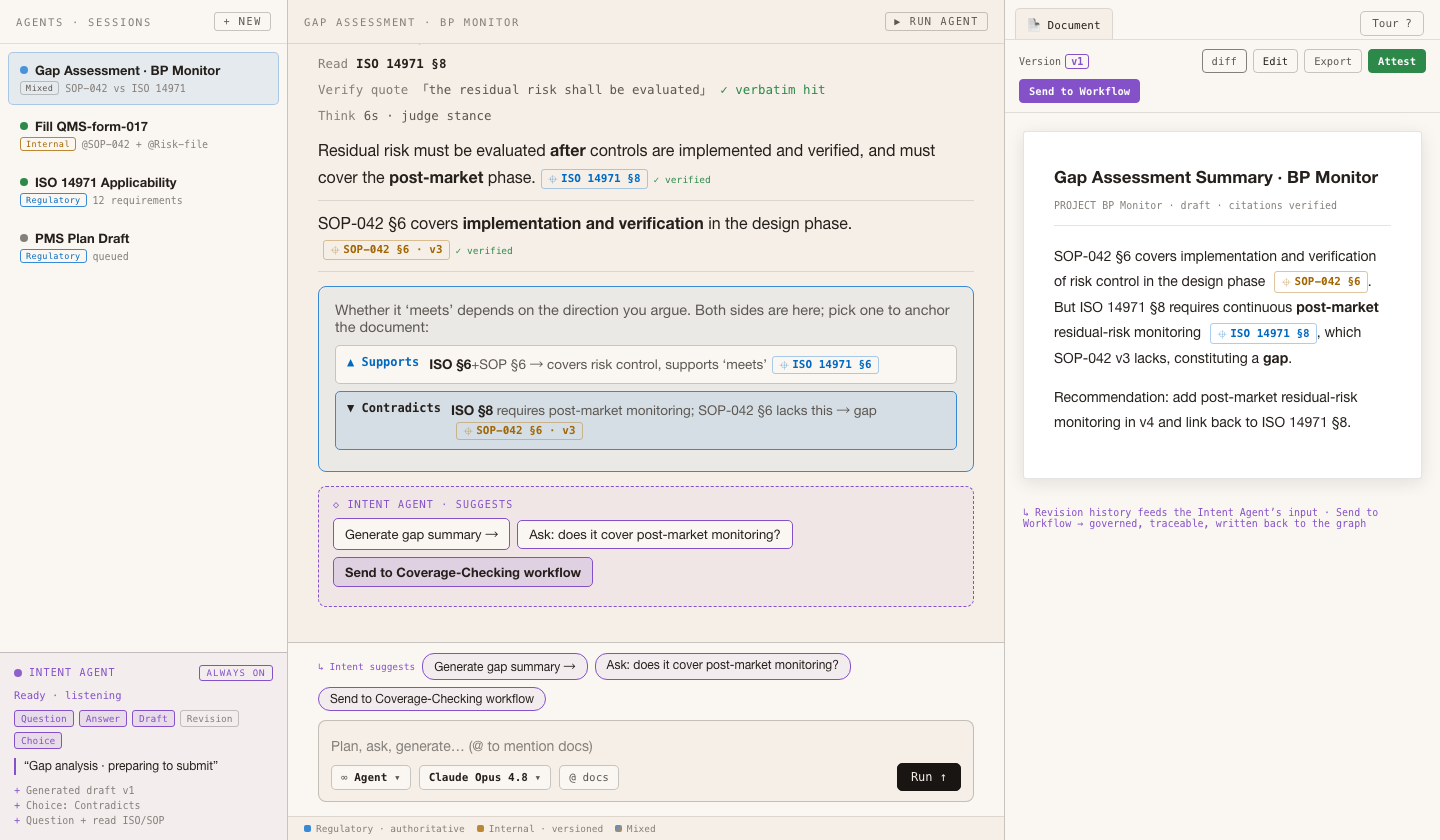
Req: editable deliverable + lifecycle
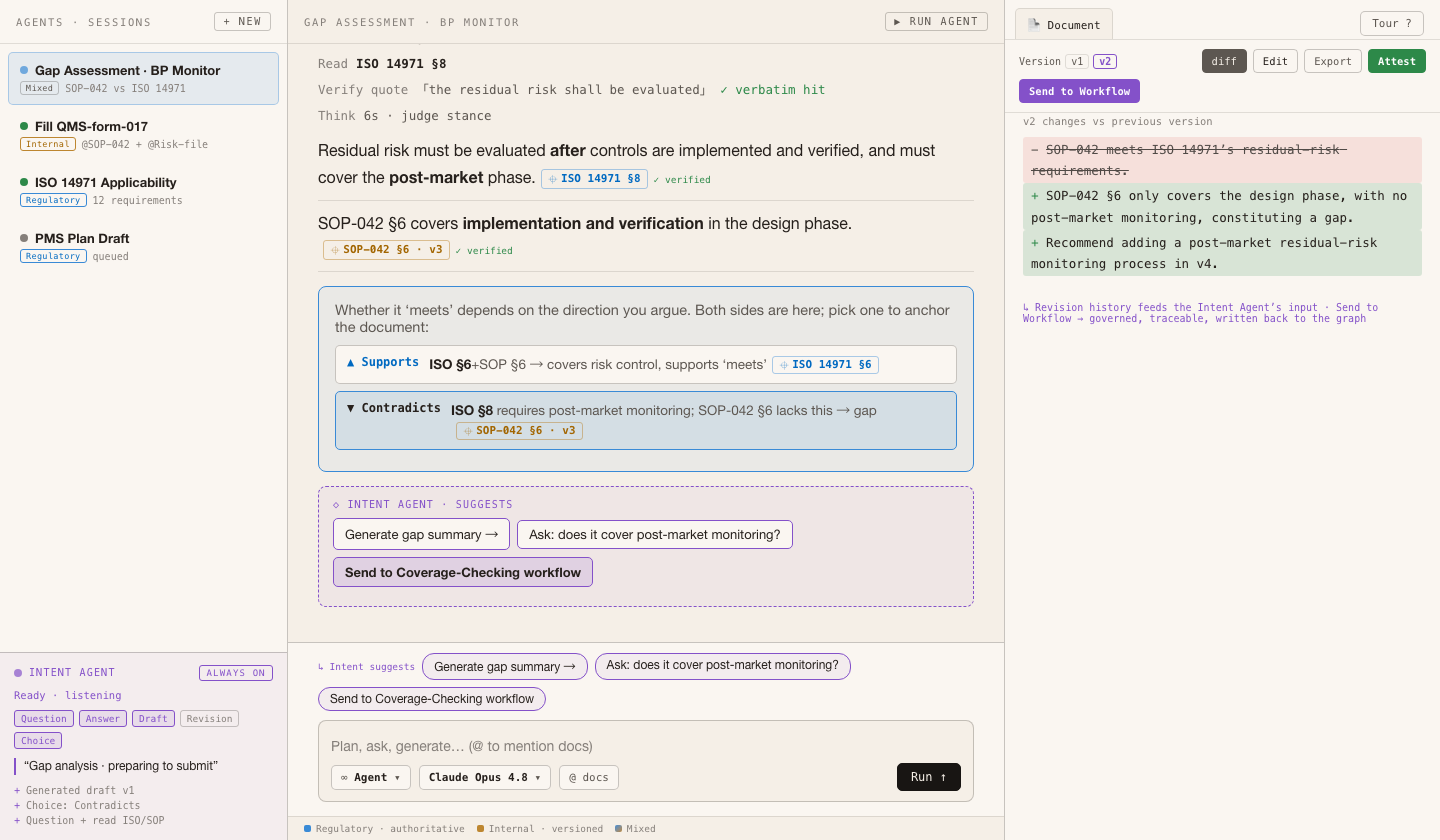
Req: revisions traceable · fed back to the intent agent
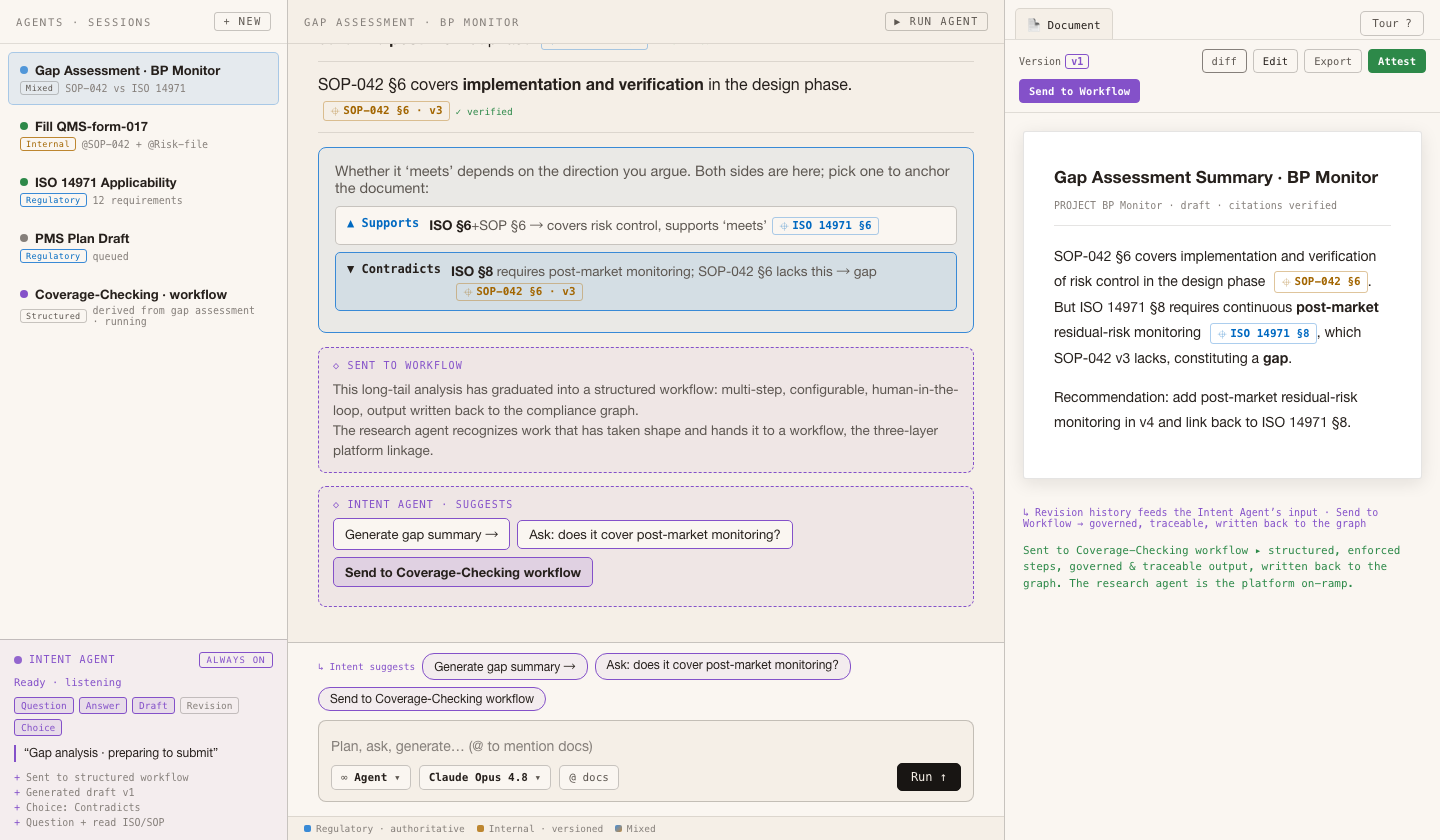
Req: three-layer linkage (research agent = platform on-ramp)
WHY THIS LAYOUT · ON THE AGENT-IDE PARADIGM
Why this design: borrow the Cursor / Claude paradigm, add a compliance-only layer
- Three columns: left agent sessions / center conversation+run / right artifact editor CURSOR · CLAUDE DESKTOP
- Parallel sessions + model picker + @-mention docs CURSOR · CLAUDE
- Cite to a specific paragraph, click to verify HARVEY
- Atomic claims, each with provenance HEBBIA
- Per-block accept + version / diff GEMINI IN DOCS · CURSOR
- Every claim is verbatim-verified backend; abstain if ungrounded (Cursor verifies code, not facts)
- Always-on intent agent: keeps inferring what you're arguing, proactively offers both directions (Cursor / Claude don't)
- Everything auditable: run log + version history + attestation → Audit Graph
Cursor / Claude Desktop proved the agent-IDE interaction works; bring it to compliance and add “verifiable + intent-aware + auditable”. That is a Cursor for compliance docs.
THE ONE TAKEAWAY
A verifiable source is the foundation of trust.
The baseline already ships in production; the frontier, supportiveness, is solved with the intent agent. Make the near field solid, advance the rest by v1 → v2 → v3.